DeepSeek Strikes Again: does its new Open-Source AI Model Beat DALL-E …
페이지 정보

본문
DeepSeek LM fashions use the same architecture as LLaMA, an auto-regressive transformer decoder model. To facilitate the efficient execution of our mannequin, we provide a devoted vllm answer that optimizes efficiency for operating our mannequin effectively. For the feed-forward network parts of the mannequin, they use the DeepSeekMoE architecture. Its release comes simply days after DeepSeek made headlines with its R1 language mannequin, which matched GPT-4's capabilities while costing simply $5 million to develop-sparking a heated debate about the present state of the AI industry. Just days after launching Gemini, Google locked down the operate to create photos of people, admitting that the product has "missed the mark." Among the many absurd results it produced had been Chinese combating within the Opium War dressed like redcoats. Through the pre-coaching state, training DeepSeek-V3 on each trillion tokens requires only 180K H800 GPU hours, i.e., 3.7 days on our personal cluster with 2048 H800 GPUs. DeepSeek claims that DeepSeek V3 was trained on a dataset of 14.Eight trillion tokens.
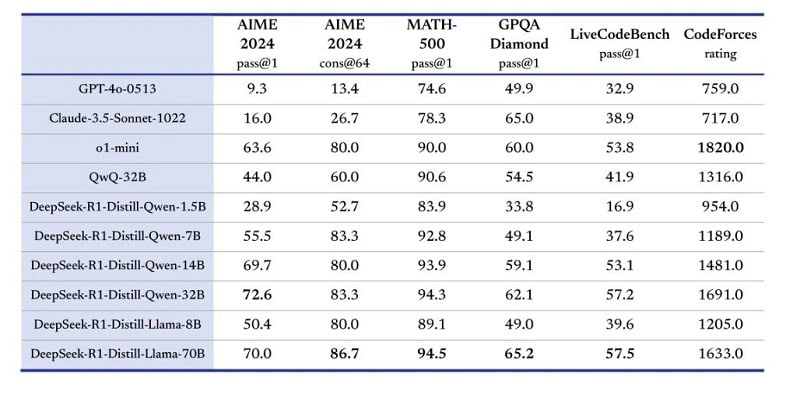 93.06% on a subset of the MedQA dataset that covers main respiratory diseases," the researchers write. The opposite main model is DeepSeek R1, which makes a speciality of reasoning and has been capable of match or surpass the performance of OpenAI’s most superior fashions in key checks of mathematics and programming. The truth that the mannequin of this quality is distilled from DeepSeek’s reasoning mannequin collection, R1, makes me more optimistic concerning the reasoning model being the true deal. We have been additionally impressed by how properly Yi was able to clarify its normative reasoning. DeepSeek implemented many tricks to optimize their stack that has solely been executed nicely at 3-5 different AI laboratories on the earth. I’ve not too long ago found an open supply plugin works effectively. More results could be discovered within the analysis folder. Image era seems robust and comparatively correct, though it does require cautious prompting to attain good outcomes. This pattern was consistent in different generations: good prompt understanding however poor execution, with blurry photos that really feel outdated considering how good current state-of-the-art image generators are. Especially good for story telling. Producing methodical, cutting-edge research like this takes a ton of work - buying a subscription would go a great distance towards a deep, meaningful understanding of AI developments in China as they happen in actual time.
93.06% on a subset of the MedQA dataset that covers main respiratory diseases," the researchers write. The opposite main model is DeepSeek R1, which makes a speciality of reasoning and has been capable of match or surpass the performance of OpenAI’s most superior fashions in key checks of mathematics and programming. The truth that the mannequin of this quality is distilled from DeepSeek’s reasoning mannequin collection, R1, makes me more optimistic concerning the reasoning model being the true deal. We have been additionally impressed by how properly Yi was able to clarify its normative reasoning. DeepSeek implemented many tricks to optimize their stack that has solely been executed nicely at 3-5 different AI laboratories on the earth. I’ve not too long ago found an open supply plugin works effectively. More results could be discovered within the analysis folder. Image era seems robust and comparatively correct, though it does require cautious prompting to attain good outcomes. This pattern was consistent in different generations: good prompt understanding however poor execution, with blurry photos that really feel outdated considering how good current state-of-the-art image generators are. Especially good for story telling. Producing methodical, cutting-edge research like this takes a ton of work - buying a subscription would go a great distance towards a deep, meaningful understanding of AI developments in China as they happen in actual time.
This reduces the time and computational sources required to confirm the search house of the theorems. By leveraging AI-pushed search results, it aims to deliver extra correct, personalised, and context-conscious solutions, potentially surpassing traditional keyword-based mostly serps. Unlike traditional on-line content material similar to social media posts or search engine results, textual content generated by massive language fashions is unpredictable. Next, they used chain-of-thought prompting and in-context learning to configure the model to score the standard of the formal statements it generated. For example, here is a face-to-face comparison of the photographs generated by Janus and SDXL for the prompt: A cute and adorable child fox with huge brown eyes, autumn leaves in the background enchanting, immortal, fluffy, shiny mane, Petals, fairy, highly detailed, photorealistic, cinematic, pure colours. For one instance, consider evaluating how the DeepSeek V3 paper has 139 technical authors. For now, the most worthy part of DeepSeek V3 is probably going the technical report. Large Language Models are undoubtedly the biggest half of the current AI wave and is at present the realm where most research and funding goes in direction of. Like all laboratory, Free Deepseek Online chat certainly has different experimental objects going within the background too. These costs aren't essentially all borne immediately by DeepSeek, i.e. they may very well be working with a cloud supplier, however their cost on compute alone (earlier than something like electricity) is no less than $100M’s per year.
 DeepSeek V3 can handle a variety of textual content-primarily based workloads and tasks, like coding, translating, and writing essays and emails from a descriptive prompt. Yes it is better than Claude 3.5(currently nerfed) and ChatGpt 4o at writing code. My analysis primarily focuses on natural language processing and code intelligence to enable computer systems to intelligently course of, understand and generate both pure language and programming language. The lengthy-term analysis purpose is to develop artificial common intelligence to revolutionize the way computers interact with people and handle advanced tasks. Tracking the compute used for a mission simply off the final pretraining run is a very unhelpful solution to estimate precise cost. This is probably going DeepSeek’s only pretraining cluster and they have many different GPUs which can be both not geographically co-located or lack chip-ban-restricted communication tools making the throughput of other GPUs lower. The paths are clear. The overall quality is better, the eyes are realistic, and the main points are easier to identify. Why this is so impressive: The robots get a massively pixelated picture of the world in front of them and, nonetheless, are capable of routinely study a bunch of refined behaviors.
DeepSeek V3 can handle a variety of textual content-primarily based workloads and tasks, like coding, translating, and writing essays and emails from a descriptive prompt. Yes it is better than Claude 3.5(currently nerfed) and ChatGpt 4o at writing code. My analysis primarily focuses on natural language processing and code intelligence to enable computer systems to intelligently course of, understand and generate both pure language and programming language. The lengthy-term analysis purpose is to develop artificial common intelligence to revolutionize the way computers interact with people and handle advanced tasks. Tracking the compute used for a mission simply off the final pretraining run is a very unhelpful solution to estimate precise cost. This is probably going DeepSeek’s only pretraining cluster and they have many different GPUs which can be both not geographically co-located or lack chip-ban-restricted communication tools making the throughput of other GPUs lower. The paths are clear. The overall quality is better, the eyes are realistic, and the main points are easier to identify. Why this is so impressive: The robots get a massively pixelated picture of the world in front of them and, nonetheless, are capable of routinely study a bunch of refined behaviors.
- 이전글Deepseek - The Story 25.02.18
- 다음글BasariBet Casino Oyunlarından En İyi Şekilde Yararlanmak İçin Nihai Rehber 25.02.18
댓글목록
등록된 댓글이 없습니다.