What is DeepSeek, the Brand new AI Challenger?
페이지 정보

본문
What's DeepSeek Coder and what can it do? Alfred might be configured to send textual content directly to a search engine or ChatGPT from a shortcut. Regardless that, ChatGPT has dedicated AI video generator. Many individuals evaluate it to Deepseek R1, and a few say it’s even better. Hermes 3 is a generalist language model with many enhancements over Hermes 2, including advanced agentic capabilities, much better roleplaying, reasoning, multi-flip conversation, lengthy context coherence, and improvements throughout the board. As for Chinese benchmarks, apart from CMMLU, a Chinese multi-subject multiple-alternative job, DeepSeek-V3-Base additionally reveals better performance than Qwen2.5 72B. (3) Compared with LLaMA-3.1 405B Base, the most important open-source model with 11 occasions the activated parameters, DeepSeek-V3-Base additionally exhibits significantly better efficiency on multilingual, code, and math benchmarks. Note that as a result of changes in our evaluation framework over the past months, the efficiency of DeepSeek-V2-Base exhibits a slight distinction from our previously reported results. What is driving that hole and the way may you expect that to play out over time? Nous-Hermes-Llama2-13b is a state-of-the-art language model effective-tuned on over 300,000 directions. This model was high-quality-tuned by Nous Research, with Teknium and Emozilla main the effective tuning course of and dataset curation, Redmond AI sponsoring the compute, and several other contributors.
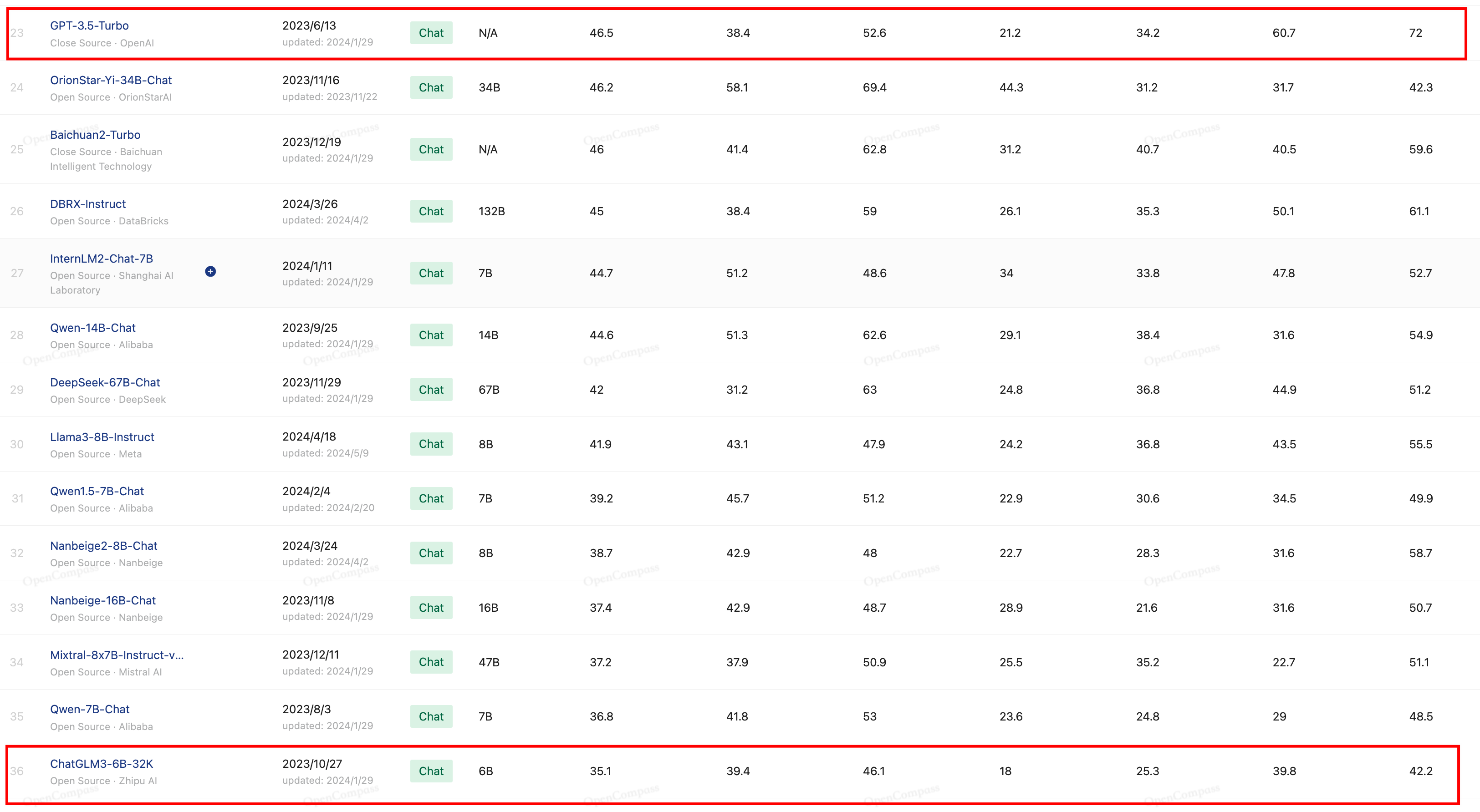 Using the SFT knowledge generated within the previous steps, the DeepSeek staff nice-tuned Qwen and Llama models to reinforce their reasoning abilities. This enables for more accuracy and recall in areas that require a longer context window, along with being an improved model of the previous Hermes and Llama line of models. The byte pair encoding tokenizer used for Llama 2 is pretty standard for language fashions, and has been used for a fairly very long time. Strong Performance: DeepSeek's models, together with DeepSeek Chat, DeepSeek-V2, and DeepSeek-R1 (targeted on reasoning), have proven impressive performance on various benchmarks, rivaling established models. The Hermes three sequence builds and expands on the Hermes 2 set of capabilities, together with extra highly effective and reliable operate calling and structured output capabilities, generalist assistant capabilities, and improved code technology abilities. The ethos of the Hermes collection of fashions is targeted on aligning LLMs to the consumer, with powerful steering capabilities and control given to the top consumer. This ensures that users with excessive computational calls for can nonetheless leverage the model's capabilities efficiently.
Using the SFT knowledge generated within the previous steps, the DeepSeek staff nice-tuned Qwen and Llama models to reinforce their reasoning abilities. This enables for more accuracy and recall in areas that require a longer context window, along with being an improved model of the previous Hermes and Llama line of models. The byte pair encoding tokenizer used for Llama 2 is pretty standard for language fashions, and has been used for a fairly very long time. Strong Performance: DeepSeek's models, together with DeepSeek Chat, DeepSeek-V2, and DeepSeek-R1 (targeted on reasoning), have proven impressive performance on various benchmarks, rivaling established models. The Hermes three sequence builds and expands on the Hermes 2 set of capabilities, together with extra highly effective and reliable operate calling and structured output capabilities, generalist assistant capabilities, and improved code technology abilities. The ethos of the Hermes collection of fashions is targeted on aligning LLMs to the consumer, with powerful steering capabilities and control given to the top consumer. This ensures that users with excessive computational calls for can nonetheless leverage the model's capabilities efficiently.
Resulting from our environment friendly architectures and complete engineering optimizations, DeepSeek-V3 achieves extremely high training efficiency. So whereas various coaching datasets improve LLMs’ capabilities, additionally they increase the chance of producing what Beijing views as unacceptable output. While many leading AI corporations rely on extensive computing energy, DeepSeek claims to have achieved comparable outcomes with considerably fewer sources. Many firms and researchers are engaged on growing powerful AI methods. These models are designed for text inference, and are used in the /completions and /chat/completions endpoints. However, it can be launched on devoted Inference Endpoints (like Telnyx) for scalable use. Explaining the platform’s underlying know-how, Sellahewa mentioned: "DeepSeek, like OpenAI’s ChatGPT, is a generative AI tool capable of creating text, pictures, programming code, and fixing mathematical problems. It’s a strong tool for artists, writers, and creators in search of inspiration or assistance. While R1 isn’t the first open reasoning mannequin, it’s more capable than prior ones, corresponding to Alibiba’s QwQ. Seo isn’t static, so why should your tactics be? 🎯 Why Choose DeepSeek v3 R1? South Korea bans Deepseek AI in authorities defense and commerce sectors China-based mostly synthetic intelligence (AI) firm Deepseek is quickly gaining prominence, but rising safety issues have led multiple international locations to impose restrictions.
This mannequin achieves state-of-the-art performance on a number of programming languages and benchmarks. While specific languages supported should not listed, DeepSeek Coder is skilled on an unlimited dataset comprising 87% code from a number of sources, suggesting broad language assist. A general use mannequin that maintains excellent normal activity and conversation capabilities whereas excelling at JSON Structured Outputs and improving on a number of other metrics. This is a basic use mannequin that excels at reasoning and multi-turn conversations, with an improved give attention to longer context lengths. A normal use mannequin that combines superior analytics capabilities with an unlimited 13 billion parameter count, enabling it to carry out in-depth information analysis and assist advanced determination-making processes. Customary Model Building: The first GPT mannequin with 671 billion parameters is a strong AI that has the least lag time. It is skilled on 2T tokens, composed of 87% code and 13% natural language in both English and Chinese, and is available in various sizes as much as 33B parameters. For prolonged sequence fashions - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp robotically. Have you ever set up agentic workflows?
- 이전글Top Online Casino Video games To Gamble For Actual Cash In 2025 25.02.19
- 다음글Christmas Love - Four Decades Ago In Vietnam 25.02.19
댓글목록
등록된 댓글이 없습니다.